Kadaster and the University of Twente (UT) have joined forces to operate at the forefront of knowledge about federated data; the goal is to advance the research field and develop methods and techniques to extract, combine, and analyze information from distributed data sources while accounting for the principles of ethical conduct, scientific integrity, and open science, to benefit the society.
To realize that goal, Kadaster and UT work together on UTKa DataLab project under the umbrella of CVD (Centrum voor Veiligheid en Digitalisering), a collaborative knowledge centre based in Apeldoorn, uniting educational institutions, businesses, and public organisations to address challenges in security and digital transformation.
Research themes
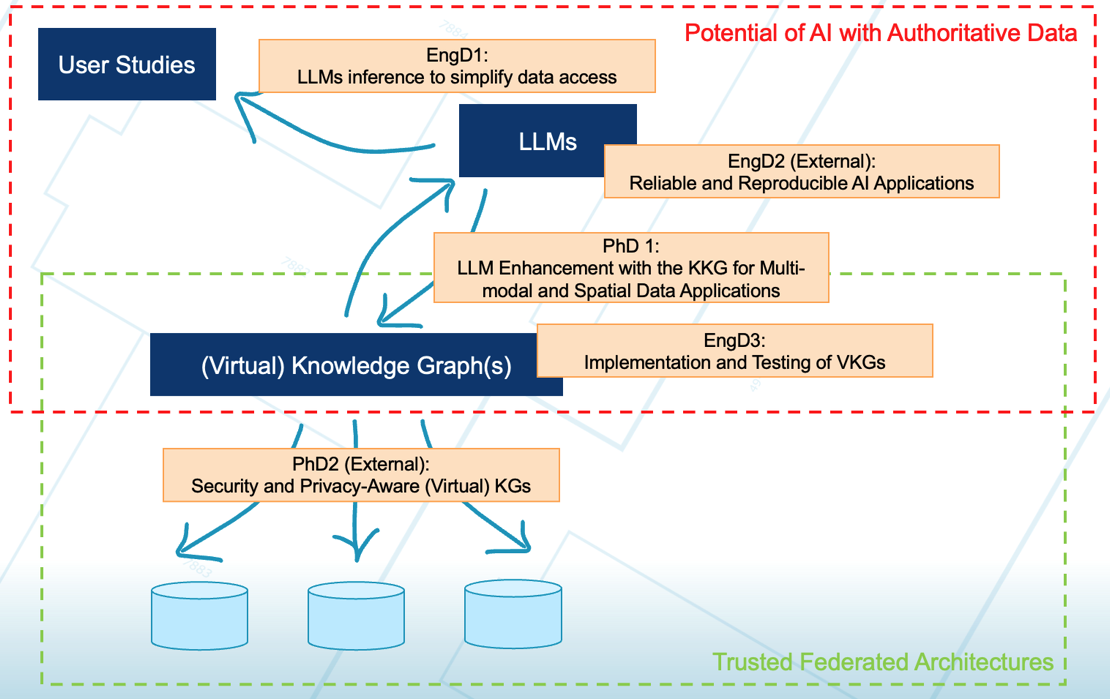
UTKa DataLab focuses on two major research themes to advance the use of AI and improve data infrastructure. These themes address key challenges in applying AI to authoritative data and creating secure, federative data-sharing systems.
1. The potential of AI with authoritative data
AI and Large Language Models (LLMs), in particular, present significant opportunities for improving the use of authoritative data in the government context. However, current implementations face challenges such as hallucinations and limited explainability. This theme explores how LLMs can be combined with knowledge graphs (KGs) to provide more explainable and trustworthy AI applications.
2. Trusted Federative Data Infrastructures
As organizations increasingly rely on data sharing, there is a growing need for secure and trustworthy data infrastructures that respect data privacy and sovereignty. This theme focuses on designing and implementing (virtual) knowledge graph (VKG) infrastructures that allow efficient data querying without data replication.